
Fundamentals of Object Detection
Object Detection
Ability to detect multiple classes of objects and identify them within a best possible concise bounding boxes in an image or video or live camera feed. There are various algorithms to achieve object detection like R-CNN, Fast R-CNN, Faster R-CNN, SSD and YOLO.
For eg: let’s classify vehicles and persons in this image. Generally the classification and location of multiple objects is known as Object detection.
( Image Classification + Image Localization ) = object detection
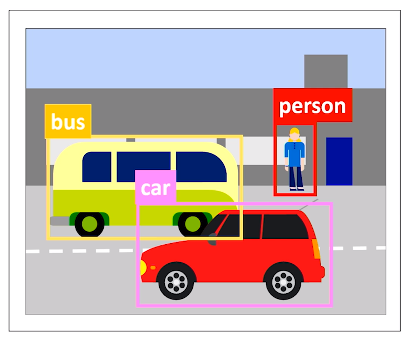
Fundamentally the solution is to generate outputs that indicate probabilities of the detected object to be a particular class and location of bounding box containing that object.
Now here we use a convention to denote target locations of detected object based on the presumed top left coordinate (0,0) in the image and locations as X, Y coordinate for center of bounding box.
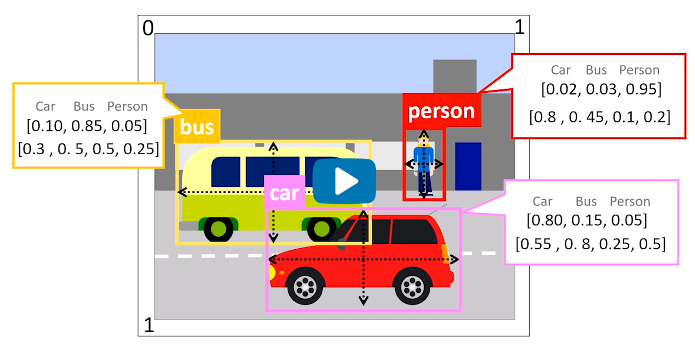
To clarify, in the image:

first array of values [0.10, 0.85, 0.05] represent the generated probabilities of the detected object classes in range (0-1) totalling 1. So the detected object was classified as a “car” by 10%, “bus” by 85% and “person” by 5%. Hence the maximum probability of 85% being “bus” was selected.
Similarly, the second array of values [0.3, 0.5, 0.5, 0.25] represent the width and height of bounding box relative to the size of the overall image. So the center of the “bus” is around 0.3 from the left of image, 0.5 from top, 0.5 as wide as image and 0.25 as tall as the image.
Now to understand the process of object detection, we need to understand how to locate and classify multiple objects in an image. Out of various approaches, we take a look at some of the standard approaches.
Applying a classification model to multiple regions of the same image. And this could be achieved by using the Sliding Windows approach. Here we create usually a square shaped window and use it place it in a specific region of the image; mostly starting at the top left part like in the figure below.
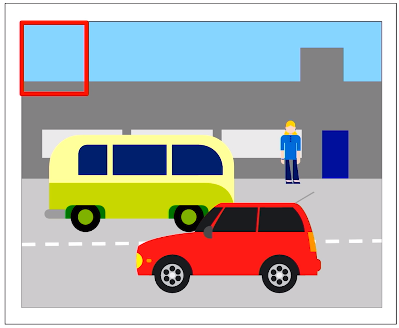
Then feed this into a convolutional neural network to classify this patch of the image. And we slide the window along to the neighbouring regions and continue the process to classify all of the window size regions in the image. And we can repeat the same process with different sized windows or on the rescaled versions of the image size so that we can detect objects of varying sizes. Now the only problem with this is that it is computationally impractical for a convolutional neural network to apply classifiers for every position of the window.
Thank you for reading. Please leave comments if you have any. Good day!


